運算式與函式
運算式(expressions)已經在查詢敘述中使用過,例如算數運算與「WHERE」子句中的條件判斷。雖然目前只有討論查詢資料的部份,不過你在任何地方都有可能使用運算式來完成你的工作。一個運算式中可以包含值(literal values)、運算子和函式,都會在這裡討論它們的細節與應用。
1 值與運算式
不論在執行查詢或資料異動的時候,你都可能會使用各種不同種類的值(literal values)來完成你的工作:
不同種類的值會有不同的用法與規定,可以搭配使用的運算子和函式也不一樣。根據資料類型可以分為下列幾種:
數值:可以用來執行算數運算的數值,包含整數與小數,分為精確值與近似值兩種
字串:使用單引號或雙引號包圍的文字
日期\/時間:使用單引號或雙引號包圍的日期或時間
空值:使用「NULL」表示的值
布林值:「TRUE」或「1」表示「真」,「FALSE」或「0」表示「假」
1.1 數值
數值分為「精確值(exact-value)」與「近似值(approximate-value)」兩種。精確值在使用時不會因為進位而產生差異;使用近似值的時候,可能會因為進位而產生些微的差異。精確值使用一個明確的數字來表示一個整數或小數數值:
整數:沒有小數的數字,範圍從-9223372036854775808到9223372036854775807
小數:包含小數的數字,整數範圍與上面一樣,小數位數最多可以有30個
一般來說,使用精確值在執行各種算數運算的時候,所得到的結果都不會有誤差的問題,你只要特別注意範圍就可以了。例如下列這個比較奇怪的查詢需求: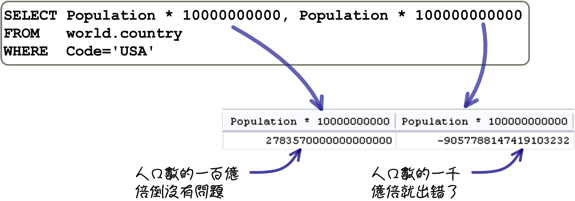
包含小數的數字,在整數部份的限制與整數相同,小數位數會有這樣的限制: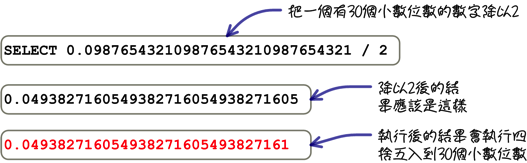
近似值的的數字通常稱為「科學表示法」,它使用下列的方式來表示一個數值:
這兩種表示方式所代表的數值是這樣計算的:
XE+Y,X * 10Y,例如5E+3,代表的數字為5000
XE-Y,X * 10-Y,例如5E-3,代表的數字為0.005
註:「XE+Y」格式中的「+」可以省略,例如「5E+3」與「5E3」是一樣的。
使用近似值來表示一個數值的時候,你一定要牢記它是一個「近似值」,也就是它真正儲存的數值可能不是你所看到的。下列的情況是你比較容易理解的: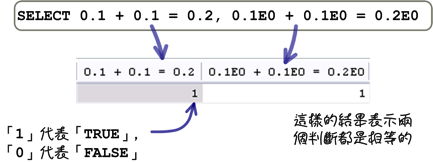
不過下列的狀況就會有不一樣的結果:
第一個運算值採用精確值的方式,所以它們一定會相等;第二個運算使用近似值的方式,所以它們不一定相等。
1.2 字串值
字串值是以單引號或雙引號包圍的文字資料,就文字資料來說,你不會拿文字執行加、減、乘、除這類的算數運算。如果你拿字串來執行算數運算的話,MySQL會先把字串中的內容轉換為數字,然後再執行算數運算: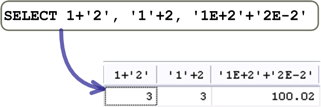
如果字串內容包含不是數值的文字,MySQL在執行轉換的時候會出現警告訊息:
字串與字串可以執行連接的運算,就是把一些字串的內容連接起來後,產生一個新的字串。要執行字串連接的工作,可以使用「||」運算子,這個運算子在條件的判斷中是「或」的意思,如果你直接使用「||」運算子連接字串的話: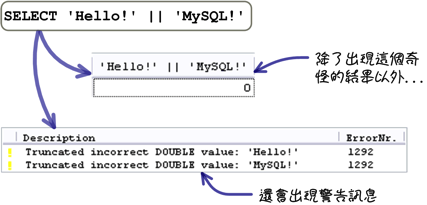
這是因為在預設的設定下,MySQL把「||」運算子當成數值的「或」運算,所以會出現這樣的情況;你可以透過設定MySQL的SQL模式,來改變這個預設處理方式:
SET sql_mode = 'PIPES_AS_CONCAT'
這個設定會把「||」運算子用在字串值的時候,把它當成「連接」運算子: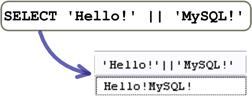
註:字串的連接也可以使用函式來處理,在這章的後面討論;另外字串的比較因為跟編碼有關,會在後面的章節詳細討論。
1.3 日期與時間值
日期與時間值(temporal values)有下列幾種:
日期:年年年年-月月-日日,’2007-01-01′
日期時間:年年年年-月月-日日 時時:分分:秒秒,’2007-01-01 12:00:00′
時間:時時:分分:秒秒:’12:00:00′
在日期與時間值中西元年的部份,可以使用四個或兩個數字。如果指定的兩個數字是「70」到「99」之間,就代表「1970」到「1999」;如果是「00」到「69」之間,就代表「2000」到「2069」。日期值中預設的分隔字元是「-」,你也可以使用「\/」,所以「2000-1-1」與「2000\/1\/1」都是正確的日期值。
日期時間資料可以使用在條件的判斷外,也可以用來「運算」,不過當然不是數值的算數運算,而是「一個日期的36天後是哪一天」這類的運算,而且只能使用「+」與「-」的運算。它的語法是:
語法中的單位可以使用下列表格中的單位關鍵字:
YEAR:年
QUARTER:季
MONTH:月
DAY:日
HOUR:時
MINUTE:分
SECOND:秒
註:上列「單位關鍵字」並沒有列出所有的單位關鍵字,全部的單位關鍵字請參考MySQL手冊「12.5. Date and Time Functions」。
1.4 NULL值
「NULL」值的處理比任何其它型態的值都來得奇怪一些,它也是一個很常見的資料,可以用來表示「未知的資料」;而且它最特別的地方是「NULL值與其它任何值都不一樣,包含NULL自己」。
「NULL」是一個SQL關鍵字,大小寫都可以。你已經知道判斷一個欄位資料是否為「NULL」值的時候,跟其它一般資料判斷是不一樣的;如果算數運算式或比較運算式中有任何「NULL」值的話,結果都會是「NULL」:
SELECT NULL = NULL, NULL < NULL, NULL != NULL, NULL + 3
上列的查詢所得到的結果全部都是「NULL」。所以在比較「NULL」值的時侯要使用下列的方式:
2 函式
在你在執行查詢或維護資料的時候,可能會有下列這個比較特殊的需求: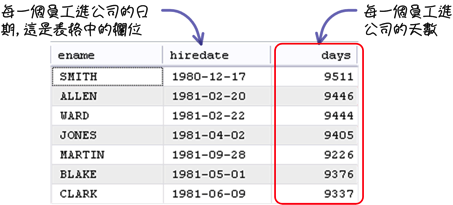
以這樣的需求來說,你當然不用自己去計算兩個日期之間的天數,MySQL提供許多不同的函式(functions),可以完成這類的需求,不論在執行查詢或維護的敘述中,都可以使用這些函式。函式基本的用法會像這樣: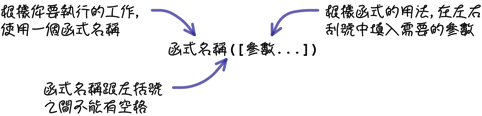
註:MySQL規定函式預設的寫法是函式名稱和左括號之間不可以有任何空格,否則會造成錯誤;你可以執行「SET sql_mode=’IGNORE_SPACE’」,這個設定讓你可以在函式名稱和左括號之間加入空格也不會出錯。
以上列「計算兩個日期之間的天數」來說,就會在查詢敘述中使用到這樣的函式: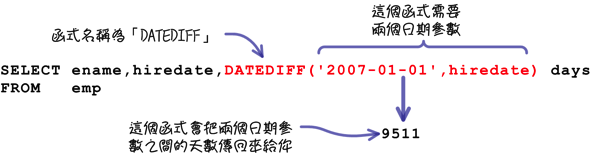
MySQL提供的函式非常多,你不用把每一個函式的名稱和用法都背起來,就算是為了參加認證考試也一樣。這個章節只有介紹「部份」函式,並不是全部,所以你在瞭解這章討論的函式以後,需要到MySQL參考手冊中的「Chapter 12. Functions and Operators」,進一步認識MySQL還有提供哪一些函式。
2.1 字串函式
字串資料的處理是一種很常見的工作,處理字串的函式也非常多,所以這裡使用分類的方式來介紹。下列是處理字串內容的相關函式:
LOWER(字串):將[字串]轉換為小寫
UPPER(字串):將[字串]轉換為大寫
LPAD(字串1, 長度, 字串2):如果[字串1]的長度小於指定的[長度],就在[字串1]左邊使用[字串2]補滿
RPAD(字串1, 長度, 字串2):如果[字串1]的長度小於指定的[長度],就在[字串1]右邊使用[字串2]補滿
LTRIM(字串):移除[字串]左邊的空白
RTRIM(字串):移除[字串]右邊的空白
TRIM(字串):移除[字串]左、右的空白
REPEAT(字串, 個數):重複[字串]指定的[個數]
REPLACE(字串1, 字串2, 字串3):將[字串1]中的[字串2]替換為[字串3]
「LPAD」與「RPAD」在處理報表資料的時候,很常用來控制報表內容的格式。例如下列的需求:
使用「LPAD」函式讓查詢後得到的字串內容向右對齊:
下列是截取字串內容的函式:
LEFT(字串, 長度):傳回[字串]左邊指定[長度]的內容
RIGHT(字串, 長度):傳回[字串]右邊指定[長度]的內容
SUBSTRING(字串, 位置):傳回[字串]中從指定的[位置]開始到結尾的內容
SUBSTRING(字串, 位置, 長度):傳回[字串]中從指定的[位置]開始,到指定[長度]的內容
下列是一個測試這些函式的查詢敘述:
下列是連接字串的函式:
CONCAT(參數 [,…]):傳回所有參數連接起來的字串
CONCAT_WS(分隔字串, 參數 [,…]):傳回所有參數連接起來的字串,參數之間插入指定的[分隔字串]
你可以使用「||」運算子連接字串,「CONCAT」函式也可以完成同樣的需求。唯一的差異是要先設定「sql_mode」為「PIPES_AS_CONCAT」後,才可以使用「||」運算子連接字串;而「CONCAT」函式不用執行任何設定就可以連接字串。
「CONCAT_WS」函式提供一種比較方便的字串連接功能,例如下列這個使用「||」運算子連接字串的查詢敘述: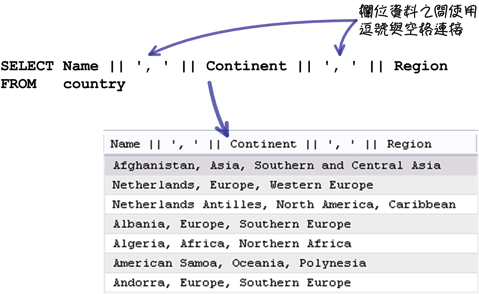
改成使用「CONCAT_WS」函式的話,就會比較簡單一些: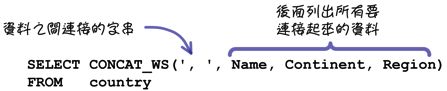
註:「CONCAT」與「CONCAT_WS」兩個函式的參數可以接受任何型態的資料,它們都會把全部的資料轉為字串後連接起來;「CONCAT」函式的參數中如果有「NULL」值,結果會是「NULL」;「CONCAT_WS」函式的參數中如果有「NULL」值,「NULL」值會被忽略。
下列是取得字串資訊的函式:
LENGTH(字串):傳回[字串]的長度(bytes)
CHAR_LENGTH(字串):傳回[字串]的長度(字元個數)
LOCATE(字串1, 字串2):傳回[字串1]在[字串2]中的位置,如果[字串2]中沒有[字串1]指定的內容就傳回0
使用「LENGTH」函式可以完成類似「國家名稱長度排行榜」的查詢: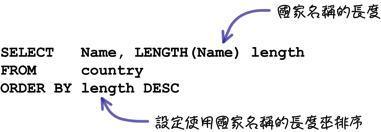
註:「LENGTH」與「CHAR_LENGTH」的差異在「第六章、字元集與資料庫」與「第七章、儲存引擎與資料型態」中會詳細的討論。
如果有需要的話,你也會搭配許多函式來完成你的工作,例如: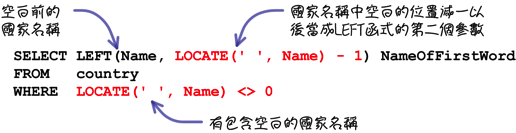
上列的敘述可以查詢「名稱是一個單字以上的國家」。
2.2 數學函式
下列是數值捨去與進位的函式:
ROUND(數字):四捨五入到整數
ROUND(數字, 位數):四捨五入到指定的位數
CEIL(數字)、CEILING(數字):進位到整數
FLOOR(數字):捨去所有小數
TRUNCATE(數字, 位數):將指定的[數字]捨去指定的[位數]
下列是一個測試這些函式的查詢敘述: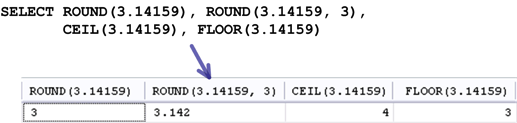
在這些函式中,「TRUNCATE」函式的用法會比較不一樣: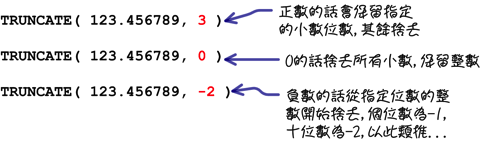
下列是算數運算的函式:
PI():圓周率
POW(數字1, 數字2)、POWER(數字, 數字2):[數字1]的[數字2]次方
RAND():亂數
SQRT(數字):[數字]的平方根
每次使用「RAND」函式的時候,它都會傳回一個大於等於0而且小於等於1的小數數字,通常會把它稱為「亂數」,這個數值是由MySQL隨機產生的。如果你的敘述中需要一個固定範圍內的亂數,可以搭配「RAND」函式套用下列的公式來產生: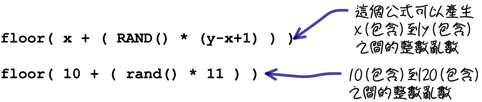
使用「RAND」函式也可以完成「隨機查詢」的需求:
註:MySQL還有提供的許多不同應用的數學函式,例如三角函式,你可以查詢MySQL參考手冊中的「12.4.2. Mathematical Functions」。
2.3 日期時間函式
下列是取得日期與時間的函式:
CURDATE():取得目前日期,相同功能:CURRENT_DATE、CURRENT_DATE()
CURTIME():取得目前時間,相同功能:CURRENT_TIME、CURRENT_TIME()
YEAR(日期):傳回[日期]的年
MONTH(日期) 數字 傳回[日期]的月
DAY(日期):傳回[日期]的日,相同功能:DAYOFMONTH()
MONTHNAME(日期):傳回[日期]的月份名稱
DAYNAME(日期):傳回[日期]的星期名稱
DAYOFWEEK(日期):傳回[日期]的星期,1到7的數字,表示星期日、一、二…
DAYOFYEAR(日期):傳回[日期]的日數,1到366的數字,表示一年中的第幾天
QUARTER(日期):傳回[日期]的季,1到4的數字,代表春、夏、秋、冬
EXTRACT(單位 FROM 日期\/時間):傳回[日期]中指定的[單位]資料
HOUR(時間):傳回[時間]的時
MINUTE(時間):傳回[時間]的分
SECOND(時間):傳回[時間]的秒
「CURDATE」與「CURTIME」可以取得目前伺服器的日期與時間,搭配其它函式就可以完成下列的「建國最久的國家排行」查詢: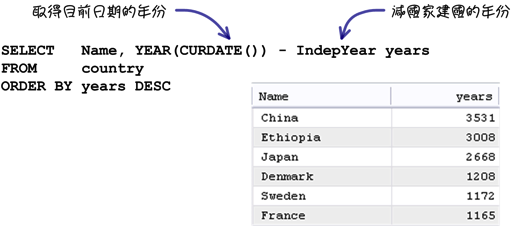
「EXTRACT」函式用來取得日期時間資料的指定「單位」,例如日期中的月份,使用的「單位」與這一章之前在「日期與時間值」中討論的一樣,這個函式讓你不用記太多「YEAR」或「MONTH」這類函式的名稱:
下列是計算日期與時間的函式:
ADDDATE(日期, 天數):傳回[日期]在指定[天數] 以後的日期
ADDDATE(日期, INTERVAL 數字 單位):傳回[日期]在指定[數字]的[單位]以後的日期
ADDTIME(日期時間, INTERVAL數字 單位):傳回[日期時間]在指定[數字]的[單位]以後的日期時間
SUBDATE(日期, 天數):傳回[日期]在指定[天數] 以前的日期
SUBDATE(日期, INTERVAL 數字 單位):傳回[日期]在指定[數字]的[單位]以前的日期
SUBTIME(日期時間, INTERVAL數字 單位):傳回[日期時間]在指定[數字]的[單位]以前的日期時間
DATEDIFF(日期1, 日期2):計算兩個日期差異的天數
在計算日期方面的函式,MySQL也提供兩種不同的用法: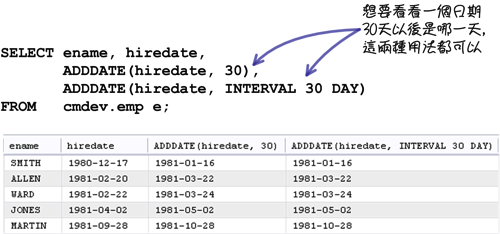
上列函式中使用的「單位」與這一章之前在「日期與時間值」中討論的一樣。
2.4 流程控制函式
在處理一般工作的時候,使用各種SQL敘述與函式,通常就可以完成你的需求;可是在實際的應用上,難免會遇到類似下列這樣比較複雜一點的需求:
像這種依照條件判斷結果而顯示不同資料的需求,可以使用下列這個「IF」函式來處理: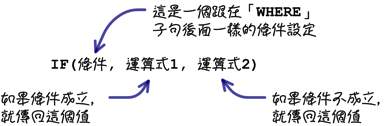
使用「IF」函式可以在查詢的時候,依照員工進公司的日期判斷是資深或是一般員工: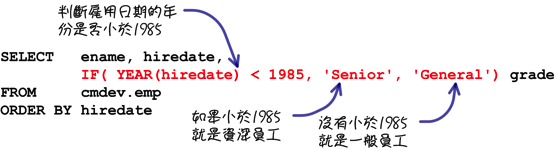
如果要依照資深員工與一般員工計算不同的獎金,也可以使用「IF」函式來完成:
「IF」函式可以用來判斷一個條件「成立」或「不成立」兩種狀況的需求;但是像下列的需求就不適合使用「IF」函式了:
如果要完成多種條件的判斷,就要使用下列的「CASE」語法,它應該不能算是一個函式,因為它的長像實在不像是一個函式: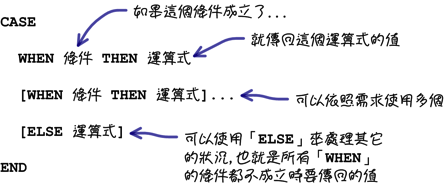
套用上列的語法,就可以判斷出所有員工的新資等級: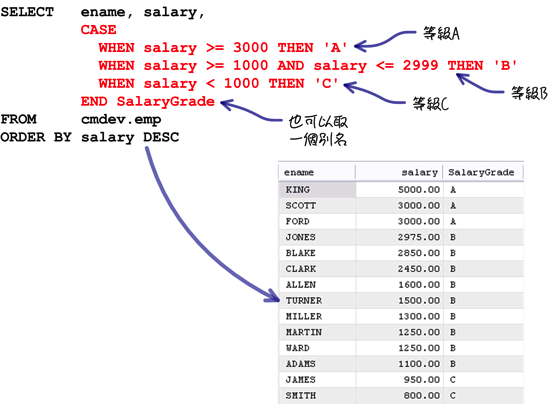
在「CASE」的語法中,要判斷一種條件就使用一個「WHEN」來完成;如果有「所有條件以外」的情況要處理的話,就可以使用「ELSE」來處理:
如果要依照員工新資等級計算不同的獎金,也可以使用「CASE」語法來完成這個需求:
「CASE」除了上列介紹的語法外,還有另外一種寫法可以處理一些比較特別的需求,例如下列七大洲的名稱與縮寫對照表:
Asia:AS
Europe:EU
Africa:AF
Oceania:OA
Antarctica:AN
North America:NA
South America:SA
如果要在SQL敘述中有類似這樣的需求,就可以使用下列這種「CASE」的語法:
套用上列的語法就可以完成這樣的查詢:
以上列的查詢來說,你也可以換成這樣的寫法:
SELECT Name, Continent,
CASE
WHEN Continent='Asia'` `THEN 'AS'
WHEN Continent='Europe'` `THEN 'EU'
WHEN Continent='Africa'` `THEN 'AF'
WHEN Continent='Oceania'` `THEN 'OA'
WHEN Continent='Antarctica'` `THEN 'AN'
WHEN Continent='North America'` `THEN 'NA'
WHEN Continent='South America'` `THEN 'SA'
END ContinentCode
FROM country
經由這樣的對照,應該可以很容易看得出來,使用哪一種寫法來完成這個查詢會好一些。
2.5 其它函式
IFNULL(參數, 運算式):如果[參數]為NULL就傳回[運算式]的值;否則傳回[參數]的值
ISNULL(參數):如果[參數]為NULL就傳回TRUE;否則傳回FALSE
當資料庫中有「NULL」資料出現的時候,就可能會發生下列這樣奇怪的結果: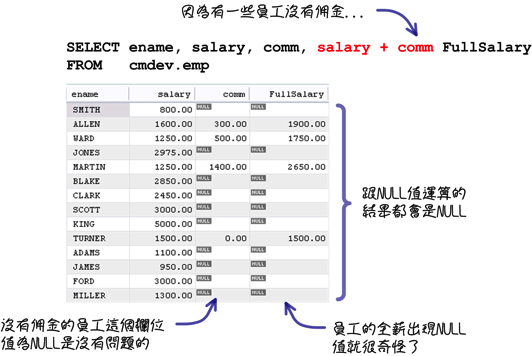
所以要得到正確的結果,就要使用「IFNULL」函式來特別處理NULL值的運算: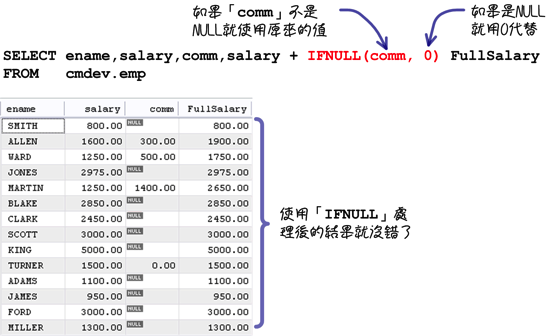
「ISNULL」函式用來判斷一個指定的資料是否為「NULL」,它的效果跟之前在「第三章、基礎查詢、條件比較」中討論的「IS NULL」和「IS NOT NULL」運算子是一樣的,你可以自己決定要使用哪一種來執行判斷。
3 群組查詢
資料庫通常是用來儲存龐大數量的資料,這也是它最善長跟主要的工作,所以查詢並計算資料的統計分析資訊也是一種很常見的需求:
你也可能會進一步的查詢更詳細的統計與分析資訊: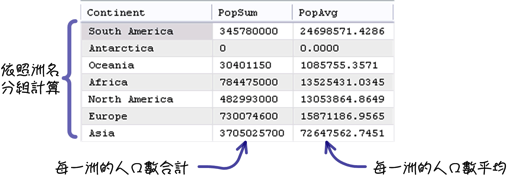
3.1 群組函式
想要完成上列討論的統計與分析查詢,你會用到下列的「群組函式」:
MAX(運算式):最大值
MIN(運算式):最小值
SUM(運算式):合計
AVG(運算式):平均
COUNT([DISTINCT]*|運算式):使用「DISTINCT」時,重複的資料不會計算;使用[*]時,計算表格紀錄的數量:使用[運算式]時,計算的數量不會包含「NULL」值
使用上列的群組函式可以很容易的查詢需要的統計與分析資訊:
這些函式套用在數值資料時會比較明確一些,把它們用在日期資料也是可以完成「員工最早和最晚進公司的日期」的查詢需求: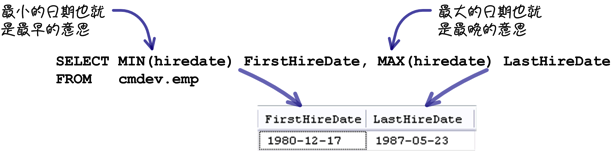
在這些群組函式中,「COUNT」函式的用法會比較不一樣:
利用「COUNT」函式的特性,也可以查詢一些特別的資訊:
3.2 GROUP_CONCAT函式
「GROUP_CONCAT」函式是比較特別的一個群組函式,它用來將一些字串資料「串接」起來。在執行一般查詢的時候,會根據查詢的資料,將許多紀錄傳回來給你:
使用「GROUP_CONCAT」函式的話,只會回傳一筆紀錄,這筆紀錄包含所有字串資料串接起來的內容: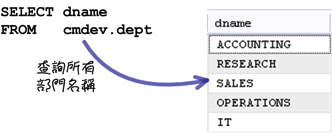
下列是「GROUP_CONCAT」函式的語法:
上列的範例是「GROUP_CONCAT」函式最簡單的用法,你還可以在函式中使用與「ORDER BY」子句一樣的用法來指定資料的排列順序: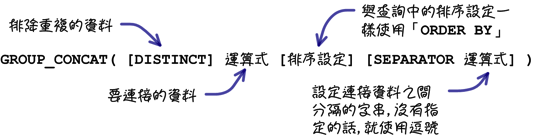
「GROUP_CONCAT」函式連接字串的時候,預設是使用逗號分隔資料,你可以自己指定分隔的字串: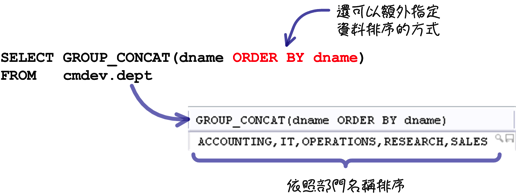
在「GROUP_CONCAT」函式中還可以使用類似在「基礎查詢、限制查詢」中討論過的「DISTINCT」來排除重複的資料,例如:
在「GROUP_CONCAT」函式中使用「DISTINCT」也會有同樣的效果:
3.3 GROUP BY與HAVING子句
在上列使用群組函式的所有範例中,都是將「FROM」子句中指定的表格當成是一整個「群組」,群組函式所處理的資料是表格中所有的紀錄。如果希望依照指定的資料來計算分組統計與分析資訊,在執行查詢的時候,可能會有下列幾種不同的結果:
上列的範例使用「GROUP BY」子句指定分組的設定,下列是分組查詢中的語法: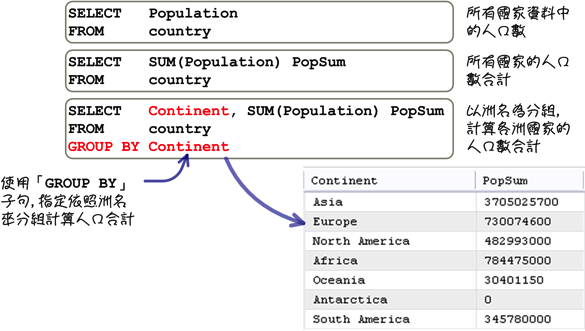
「GROUP BY」子句指定是依照你自己的需求來決定的,同樣以人口數量合計來說,不同的指定可以得到不同的統計資訊: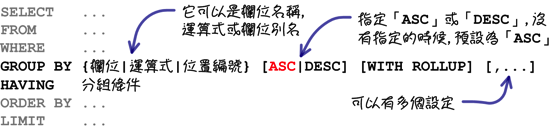
使用不同的群組函式,就可以得不同的資訊:
如果需要的話,你可以在一個查詢中,一次取得所有需要的統計與分析資訊: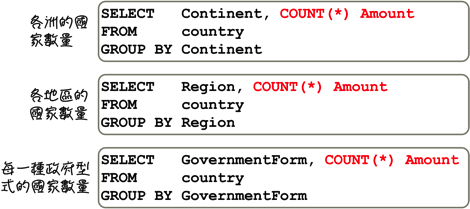
在查詢群組統計與分析資訊的時候,你可以指定多個群組設定取得更詳細的資訊:
使用「GROUP BY」指定群組的設定以後,回傳的群組查詢資料都會依照指定的群組排序,預設定排序方式是遞增排序,使用「DESC」關鍵字可以指定排序的方式為遞減排序: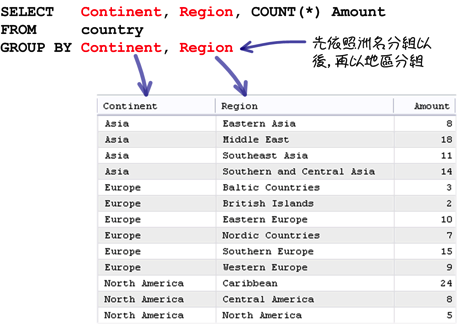
使用「GROUP BY」子句的時候可以搭配「WITH ROLLUP」: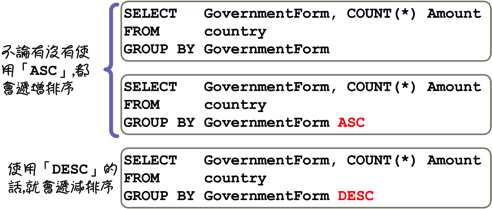
使用「WITH ROLLUP」以後,效果會作用在查詢中的每一個群組函式:
在「GROUP BY」子句中有多個群組設定的時候,你可以在最後面加入「WITH ROLLUP」:
在執行群組查詢的時候,一般的條件設定同樣使用「WHERE」子句就可以了: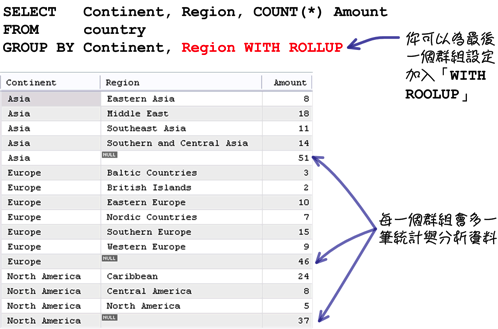
可是以類似上列的查詢來說,把查詢條件從「亞洲的地區」換成「人口合計大於一億的地區」,如果還是把條件設定放在「WHERE」子句的話:
包含群組函式的條件設定就一定要放在「HAVING」子句中:
依照需求在執行群組查詢的時候,應該不會出現下列的查詢敘述: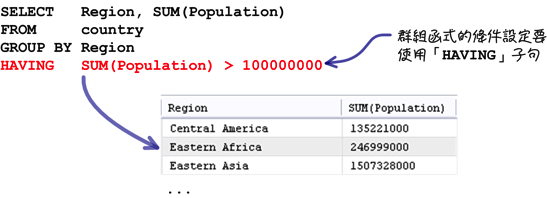
MySQL資料庫在執行上列的查詢敘述後,並不會產生任何錯誤,為了預防這樣的狀況,你可以執行下列的設定: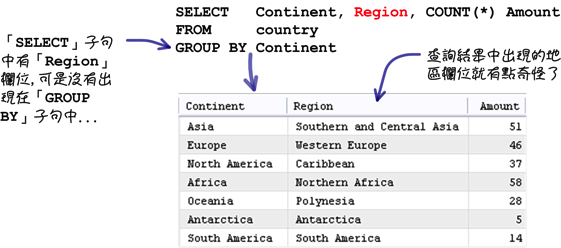
SET sql_mode = 'ONLY_FULL_GROUP_BY'
在「sql_mode」的設定中加入「ONLY_FULL_GROUP_BY」,表示多了下列的規定:
如果查詢敘述違反「ONLY_FULL_GROUP_BY」的規定,就會產生錯誤訊息: